




.gif)



.gif)


.gif)
.gif)

.gif)

.gif)




.gif)

.gif)
.gif)
.gif)

.gif)
.gif)
.gif)

CVPR 2024
Ruiqi Wu1,2, Liangyu Chen2, Tong Yang2, Chunle Guo1,*, Chongyi Li1, Xiangyu Zhang2
VCIP, CS, Nankai University1, MEGVII Technology2
Click to learn more
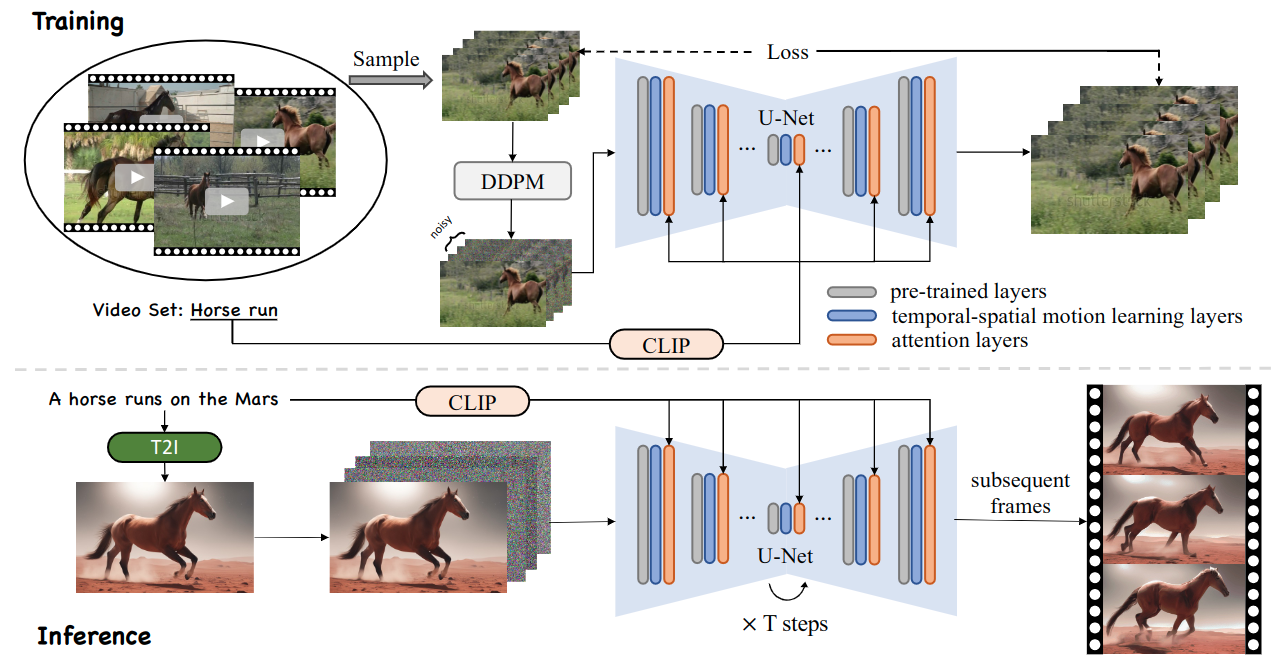
Framework of the proposed LAMP. Our LAMP learns a motion pattern from a small video set and generates videos with the learned motion, which achieves the trade-off between training burden and generation freedom. We transfer text-to-video generation to the first-frame generation and subsequent-frame prediction, i.e., decoupling a video's contents and motions. During the training stage, We add noise and compute loss functions on all but the first frame. Moreover, only the parameters of newly added layers and the query linear layers of self-attention blocks are updated when tuning. During the inference stage, we use a T2I model to generate the first frame. The tuned model only works on denoising the latent features of subsequent frames with the guidance of user prompts.
|
|
|
|
| A horse runs in the universe. | A horse runs on the Mars. | A horse runs on the road. |
|
|
|
|
| Fireworks in desert night. | Fireworks over the mountains. | Fireworks in the night city. |
|
|
|
|
| GTA5 poster, a man plays the guitar. | A woman plays the guitar. | An astronaut plays the guitar, photorealistic. |
|
|
|
|
| Birds fly in the pink sky. | Birds fly in the sky, over the sea. | Many Birds fly over a plaza. |
Our text-to-video results. The video prompts are listed, and the motion prompts are "A horse run", "Firework", "Plays the guitar", "Birds fly", respectively. Our LAMP works effectively on diverse motions. The generated videos are temporal consistent and close to the video prompts. Moreover, two advantages of LAMP can be reflected in the above results. (1) The proposed first-frame-conditioned training strategy allows us to use powerful SD-XL for first-frame generation, which is beneficial to producing highly detailed following frames. (2) Good semantic generalization properties of the diffusion model are preserved (e.g. imposing the motion "play the guitar" on GTA5-poster style) since our tuning way.
| Origin Videos | Editing Result-1 | Editing Result-2 |

|

|

|
| A girl in black runs on the road. | A man runs on the road. | |

|

|

|
| A man is dancing. | A girl in white is dancing. |
@inproceedings{wu2024lamp,
title={LAMP: Learn A Motion Pattern for Few-Shot Video Generation},
author={Wu, Ruiqi and Chen, Liangyu and Yang, Tong and Guo, Chunle and Li, Chongyi and Zhang, Xiangyu},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2024}
}
Feel free to contact us at wuruiqi AT mail.nankai.edu.cn or wuruiqi AT megvii.com
Visitor Count